
Indeed. At least the source PDF (cited in the graphic) has the data:
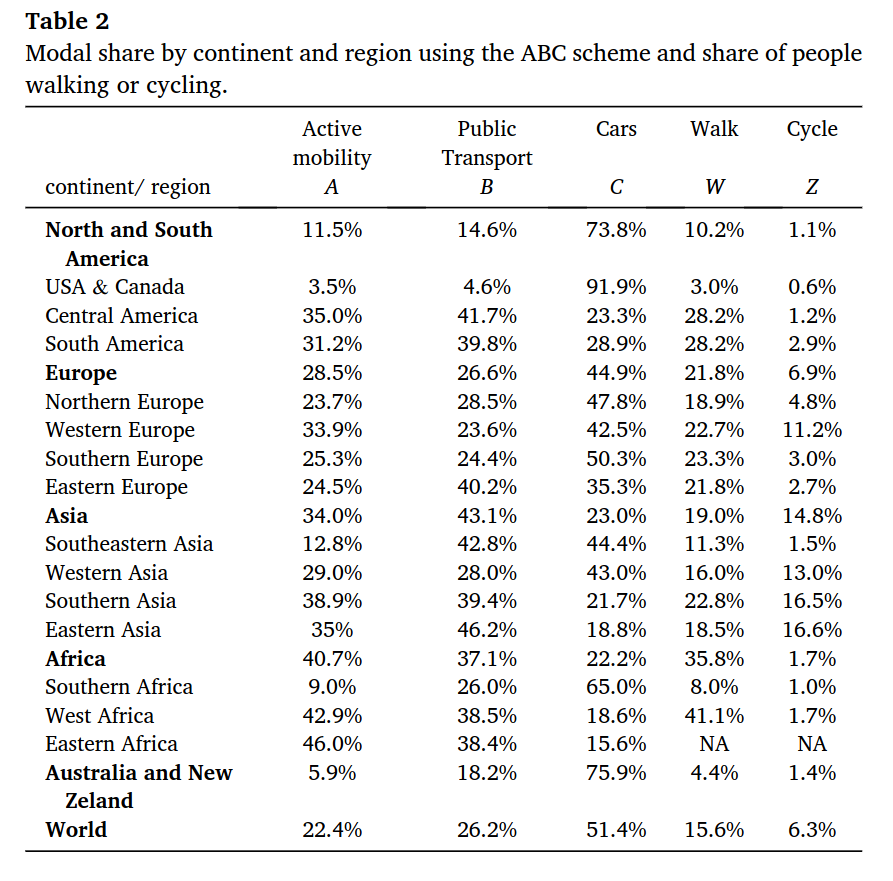
Indeed. At least the source PDF (cited in the graphic) has the data:

The authenticated encryption of HTTPS similarly protects the CDN-based web clock approach. This avoids situations where an attacker-in-the-middle tampers with insecure NTP responses, messing up your system’s clock.
Almost… there is this fun thing called a delay attack that works despite encryption! (I’ll admit that it’s probably not a practical concern.)
Anyway, the article talks about time measurements through an absurd amount of abstraction layers. Please don’t ever call this “simple” or even “cloud-native time” or the like.
If you start trying to improve this setup you’ll find so many face-palm moments. Like TCP retransmissions (which the article mentions, to be fair). You’d have to use WebRTC to avoid that, which I bet the CDN network doesn’t support. Or the fact that web browser timers have intentionally reduced precision to resist fingerprinting. (Granted, if you are still in the milliseconds range it is not a problem.)
After I fiddle with the firewall rules (or a system install or major upgrade) I usually only do a quick portscan with nmap from another box. (TCP and UDP; only IPv4 only because I disabled IPv6 completely.) There are online port-scan services too, but you never know if they also invite the bots.
I agree with others here that vulnerability-scanning your own applications seems overkill. Like with external virus scanners, I always feel they are just as likely the attack vector themselves. The more complexity, the more risk.
What I do is:
AllowUsers user whitelist, but KbdInteractiveAuthentication no should be good enough too. If the failed login attempts by the bots bother you, you could run sshd on a non-standard port.Something else I always wanted to do (but never got around doing) is to create a simple canary intrusion detection. Like, putting some important-looking “prod” host into ~/.ssh/config and a private ssh key, and configure the target host to send me a SMS instead when this key tries to log in. (Or even shut everything down automatically.) This should prevent me from becoming part of a botnet for months unnoticed, maybe.
I have a router with a few cronjobs like this:
# m h dom mon dow command
00 20 12 * * echo "check bank transactions (monthly reminder)"
00 19 15-21 * * test $(date +\%u) -eq 6 && echo "Anki learning reminder"
Cron will by default send an email with the script output. So you “just” need a non-broken email setup that forwards system emails to your main account. (Assuming you don’t self-host email too.)
This setup is useful because I have a few other cronjobs (backup scripts, and a health check for my own application) that should notify me in case of failure, and I would eventually notice that this is broken by noticing that those “calendar” emails no longer get through.

Are you this person who, at the family gathering, will loudly decline words in a long dead language they forced you to learn 50 years ago, just to call it useful?
Well the problem with Lemmy is that it doesn’t have clamfacts, so you need mastodon too.
but businesses don’t have that luxury. That’s why they use proprietary software
Wait, that doesn’t match my business experience. Those proprietary solutions are usually a collection of open source libraries and DBs and Elasticserach or Redis and whatever running Linux VMs held together with duct tape and a small amount of proprietary application code (compared to everything else) using five different open source frameworks.
Or if you buy, say, a Lasercutter, how do you think they convert the images you prepare for engraving? Their own commercial libraries they bought from someone? Because businesses don’t do open source? Nope. How do you think businesses compile the firmware that goes into their CNC machine? Borland C++? Nope.
When you use the proprietary software, they don’t tell you what went into it. That’s kind of the point - you are buying a solution and only want to know the price. When you host your own instead, you kind of need to know what goes into it, because you didn’t pay someone to do the integration for you.
Or more fundamentally: with open source, you only get what the developer wanted to build. If you want someone to build what you need, you got to be either lucky that the two things align close enough, or find a way to pay someone to focus on your needs instead of theirs. Or you can hope someone else pays someone to make it and then pays a little bit extra to also publish it open source for everyone else to use. Rarely happens, but it does happen.
Maybe my LLM detector needs an update, but only the headline triggered it. The article did the opposite for me.
Anyway, the author checks out, old github profile etc. Works in high frequency trading, which I despise because I think it is make-do work, moving money around a millisecond before anyone else has a chance, a huge technical effort with zero benefit to society compared to slower trading. I’ll file it together with adtech and bitcoin. But. The article is not about that. And I know that working in high frequency trading sure makes you qualified to talk C++ or FPGAs or anything close-to-the-metal. So, author background checks out. Verdict: not slop.

I feel old now. I can almost hear the noise of the drive trying to chew on this one.
Anyway, have some on-theme music video: BAD SECTOR by unfa (youtube.com)
The title is clickbait, but the article is well written.
It is tearing apart some points made in a talk (which I didn’t watch). The talk seems to focus on C++26 features (given that you are using C++) while the article argues why you still shouldn’t use C++ in the first place, despite the improvements. Mainly because the memory safety features are opt-in. There is also discussion about the CrowdStrike incident, and how it was more of a cultural problem than a language problem.

I heard they are investing into moonshot projects.
Yes but despite the footguns, C (not C++) is a relatively small language, not too hard to learn. And it’s the glue between kernel, system libraries, and all other languages. You don’t want to write big applications in it any more, but it’s still useful to know when you interface with existing stuff.

I agree that showing the zero level may be useful here, but… I cannot find a scientific source that shows it differently, so it’s not intentionally misleading at least. The bigger issue IMO is that it doesn’t show enough historic context (ice core data). The original article has it, or nature.org or co2science.org (though it doesn’t show the latest measurements).
Depends. I would flag it in a code review on our product, and same for most TODO comments. It’s bad practice to leave them for your team to deal with, or even for yourself two years later.
But for explorative coding (mostly just one person, things like game development or creative coding, or before finishing your branch) I think dead code warnings do more damage than they help. They make you look at things not worth looking at right now, until you figured out what you want to build. Like unused structs or imports just because you commented out some line to test something. I didn’t turn all annoyances off, but I feel I should. I have a hard time just ignoring them. I think it’s better to enable them later when the code is stabilizing, to clean up experiments that didn’t work out. When I just ignore them I also ignore a more important warnings, and waste time wondering why my stuff isn’t working while the compiler is actually telling me why.
Also, in Rust many clippy defaults are too pedantic IMO, so I turn them off for good. Here is what I currently use:
[lints.rust]
dead_code = "allow"
[lints.clippy]
new_without_default = "allow"
match_like_matches_macro = "allow"
manual_range_patterns = "allow"
comparison_chain = "allow"
collapsible_if = "allow"
collapsible_else_if = "allow"
let_and_return = "allow"
identity_op = "allow" # I'll multiply by one whenever I like!
# Just disable all style hints?
# style = "allow"
Kagi user since 2022, according to my account. I’ll admit that I rarely ever cross-check with other search engines. I like their assistants too (they are basically re-selling access to all big LLMs in their Ultimate tier). But you don’t really need those, what keeps me there are the good search results. (And the ability to easily block/raise whole domains on the results.)
Some months ago walking got suddenly painful in the lower back. Walking down a stair was only possible at half the normal speed. I am fourty-something and this made me feel very old. I did more of my usual back-strengthening exercises, but it got worse. I thought surely something is broken. When I went to the doctor she told me that I just neglected stretching, mostly the hip flexor. It went away after doing that. Apparently very common when you sit a lot, and when you do lots of running. (And I did try more running to make it go away, without stretching afterwards, lol.)
Also in Europe. I’ve heard about Grenoble (France), but there seem to be more now. Check out adfreecities.org.uk too. Most don’t seem to ban 100% of all ads, but close enough for me.
Maybe people who are used to this will become less tolerant of online ads, too.
I found it interesting that key travel time was considered, often it isn’t.
A similarly interesting article: Measure and reduce keyboard input latency with QMK on the Kinesis Advantage (2021) (Basically, took an existing keyboard and replaced the controller.)
If I’m clearly not understanding a key concept in biology
Yes, you’re misunderstanding the concept of death. Death is bad only from the individual’s point of view. It’s how life renews itself, making room for change. Nothing wrong with trying to reduce suffering, of course, but immortality clearly falls into the “nefarious reasons” category. It’s what happens when you focus too much on the individual’s perspective of life. If you want to study biology you have to consider death from a different angle.

I switched to Termux for a while too. It works. But it was a bit too fiddly. (Symlinks and permissions stuff, separate browser window, notification that it is still running, and also I never set it up to start on boot.)
I switched to BasicSync a while ago, can recommend.